Multimodal feature fusion for establishing novel 3D saliency models
The project aims to process the data of novel 3D sensors (e.g. Microsoft Kinect, Lidar, MRI, CT) available in a wide range of application fields and to fuse them with 2D image modalities to build saliency models, which are able to automatically and efficiently emphasize visually dominant regions. Such models not only tighten the region of interest for further image processing steps, but facilitate and increase the efficiency of segmentation in different application fields with available 3D sensor data, e.g. remote sensing, medical imaging, 3D reconstruction and video surveillance systems.
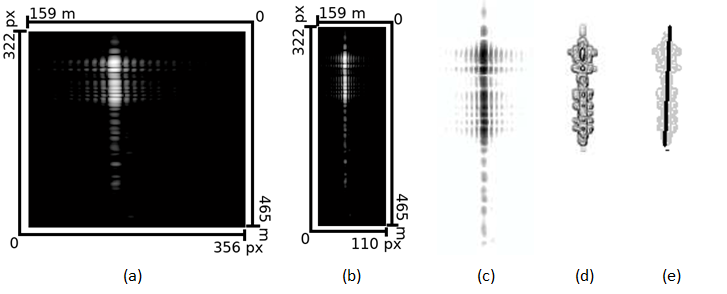
In the first year of the project the project team has accomplished research work in two main topics, the first is target classification for passive ISAR using a saliency model for target detection; the second is content-based medical image processing where multimodal sensor data is processed, using the fusion of saliency and learning-based techniques for segmentation purposes.

Publications:
[1] A. Manno-Kovacs, E. Giusti, F. Berizzi, L. Kovács, "Automatic Target Classification in Passive ISAR Range-Crossrange Images", 2018 IEEE Radar Conference (RadarConf'18), Oklahoma City, USA, April 23-27, 2018.
[2] A. Manno-Kovacs, "Direction Selective Contour Detection for Salient Objects", IEEE Transactions on Circuits and Systems for Video Technology, https://ieeexplore.ieee.org/document/8288650, accepted, 2019.
[3] A. Manno-Kovacs, E. Giusti, F. Berizzi, L. Kovács, "Image Based Robust Target Classification for Passive ISAR", IEEE Sensors Journal, vol. 19., no. 1., pp. 268-276, 2019. https://ieeexplore.ieee.org/document/8501978
[4] P. Takacs and A. Manno-Kovacs, "MRI Brain Tumor Segmentation Combining Saliency and Convolutional Network Features", 16th International Conference on Content-Based Multimedia Indexing (CBMI), La Rochelle, France, September 4-6, 2018.
[5] A. Kriston, V. Czipczer, A. Manno-Kovács, L. Kovács, Cs. Benedek and T. Szirányi, “Segmentation of multiple organs in Computed Tomography and Magnetic Resonance Imaging measurements”, 4th International Interdisciplinary 3D Conference, Pécs, Hungary, October 5-6, 2018.