AAAI Tutorial
AAAI-10 Tutorial: Reinforcement Learning Algorithms for MDPs
Sunday, July 11, 2010, 9:00 AM – 1:00 PM
Location: Atlanta Ballroom F, Seventh Floor
Slides without notes: Part 1, Part 2, Part 3, Part 4
The "slides with notes" pdfs below come in a format where every page to be shown on the big screen is followed by a page that is to be shown on the computer's private screen (i.e., they are designed for dual screen projection). We decided that the notes might be useful for the audience, so we share them with everyone. Here they come:
Slides with notes: Part 1, Part 2, Part 3, Part 4
Abstract
Reinforcement learning is a popular and highly-developed approach to artificial intelligence with a wide range of applications. By integrating ideas from dynamic programming, machine learning, and psychology, reinforcement learning methods have enabled much better solutions to large-scale sequential decision problems than had previously been possible. This tutorial will cover Markov decision processes and approximate value functions as the formulation of the reinforcement learning problem, and temporal-difference learning, function approximation, and Monte Carlo methods as the principal solution methods. The focus will be on the algorithms and their properties. Applications of reinforcement learning in robotics, game-playing, the web, and other areas will be highlighted. The main goal of the tutorial is to orient the AI researcher to the fundamentals and research topics in reinforcement learning, preparing them to evaluate possible applications and to access the literature efficiently.
|
|
Prerequisite knowledge: We will assume familiarity with basic mathematical concepts such as conditional probabilities, expected values, derivatives, vectors and matrices.
Reading material
The tutorial will follow closely the publication: Attendees would thus benefit from reading through this paper.
Attendees would thus benefit from reading through this paper.
Note that an extended, ca. 100 page long version of this short paper is expected to appear in print by the time of the conference in the AI Lectures Series of Morgan & Claypool Publishers. Here is the website of the book and you can buy it on Amazon here! If you want to check out the content before you buy, the manuscript is available from here.
Schedule
9:00-9:40 Part 0: Introduction
Contents:
- Defining and motivating the problems
- Classification of learning problems
- A quick glance at the coming attractions (what algorithms, what problems)
|
|
Main message: Sequential decision making problems are at the heart of AI and finding approximate solutions to them is a key challenge in AI
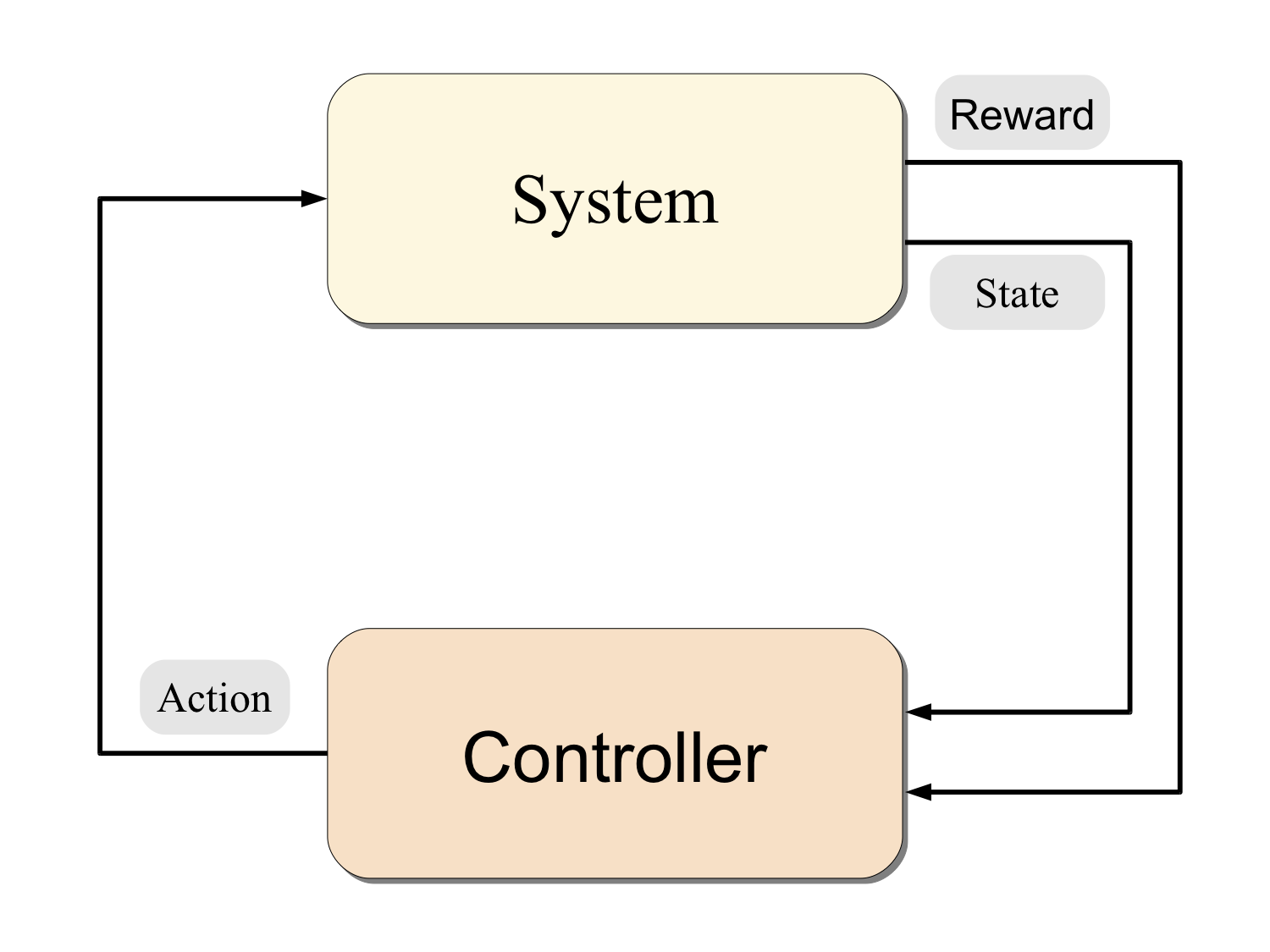
Concepts: MDPs, state, action, reward, transitions, open- and closed-loop control, the optimal control problem, state-space representation of the optimal control problem, stationary policies, value functions
Algorithms: Exhaustive enumeration of policies
Theory: Bellman equation for policies
Examples:
- OR like: Power management of computers (a 2 states MDP), queuing, inventory management
- AI like: Robot control, car driving, walking, focus of attention, information retrieval, adaptive user interfaces, ..
9:40-9:50 Break
9:50-10:30 Part I: Foundations of computing optimal decisions
Main issues studied:
- Planning under uncertainty
- Dynamic programming algorithms
- Using samples to avoid intractability (i.e., Monte-Carlo value estimation)
Main message: Dynamic programming trades off search time to memory but exact calculations lead to intractability. Sample-based methods can avoid this pitfall.
Concepts: Bellman equations (optimality, policy evaluation)
Algorithms: Value iteration, policy iteration, Monte-Carlo value estimation
Theory: Vectors=functions, contractions, fixed points, basic error bounds, sample based planning
Examples:
- For DP algorithms power management
- For Monte-Carlo: predicting power consumption, predicting the size of inventories, taxi-out times on airports
10:30-11:00 Official Break
11:00-11:50 Part II: Learning to predict values
Main issue studied: How to learn the value function of a policy over a large state space?
Lessons:
- Features, representation matter.
- Sample size matters: Overfitting/underfitting can be a problem
- Incremental vs. non-incremental methods: use incremental when the feature space is large and observations are plentiful
Concepts: Parametric (linear) function approximation, non-linear and non-parametric function approximation, incremental and non-incremental methods, on-policy and off-policy sampling, temporal differences
Algorithms: TD(lambda) for linear function approximation, GTD and variants, [R]LSTD(lambda), [R]LSPE(lambda)
Theory: Stochastic approximation, generalization error bounds
Examples: predicting power consumption, predicting the size of inventories, taxi-out times on airports
11:50-12:00 Break
12:00-12:40 Part III: Learning to control
Main issue studied: How to learn a good policy?
Lessons:
- Controlling the trade-off between exploration and exploitation is crucial for success
- Many algorithms in use, however, the case is far from being finished!
Concepts: exploration-vs.-exploitation dilemma, parametric (linear) function approximation, non-linear and non-parametric function approximation, incremental and non-incremental methods, on-policy and off-policy sampling, temporal differences
Algorithms:
- Direct methods: Q-learning, Greedy GQ, Fitted Q-iteration
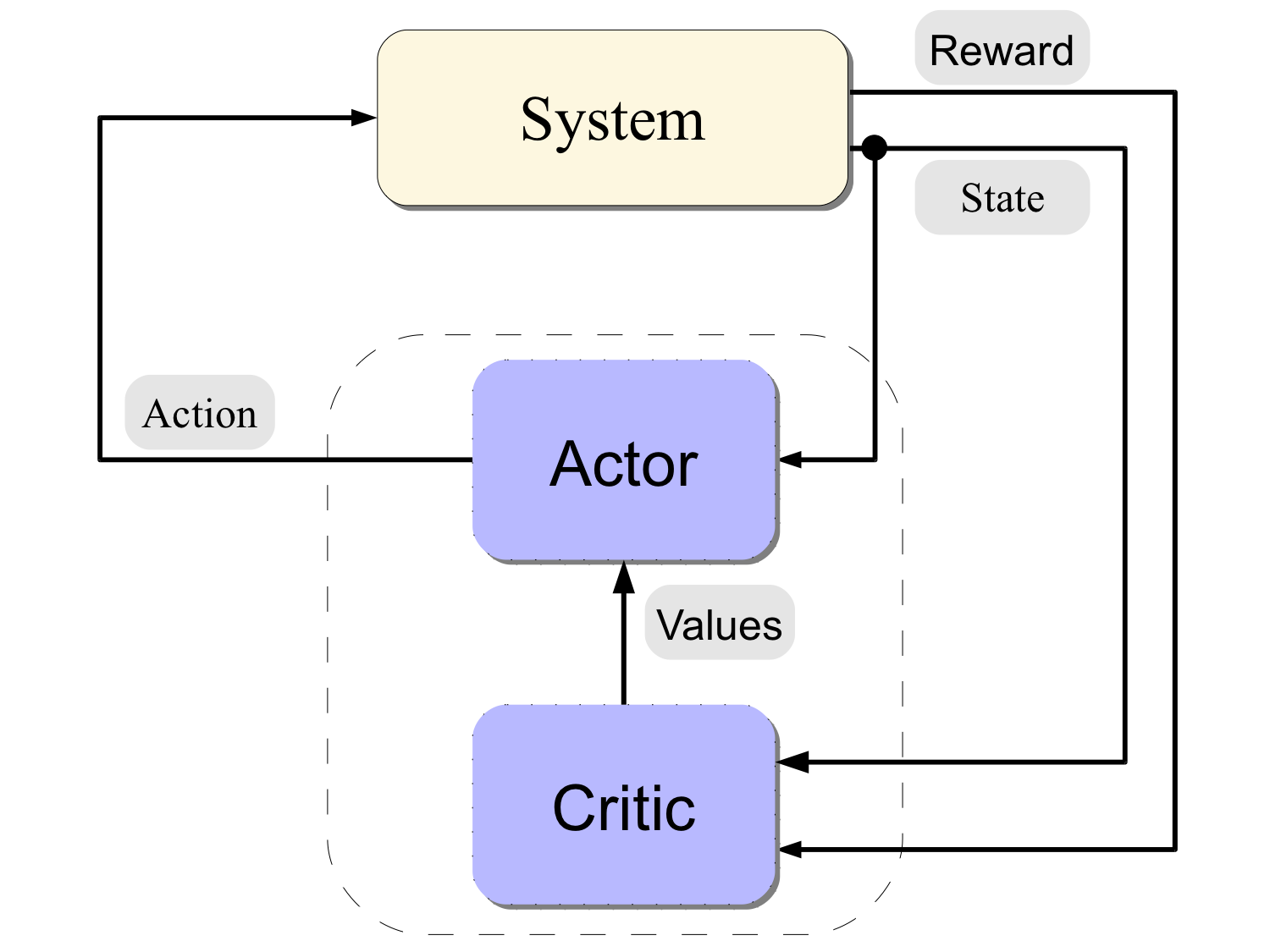
- Actor-Critic methods: Sarsa(lambda) + Natural Actor-Critic
Theory: Error propagation, error bounds, asymptotic theory
Examples: Tetris, inverted pendulum, learning to walk, inventory control, TD-Gammon
12:40-13:00 Part IV: Summary
Contents:
- Revisiting the concepts, ideas, algorithms, issues
- Guide to the available software
- Guide to the literature (what was left out)
- Surprising facts about RL